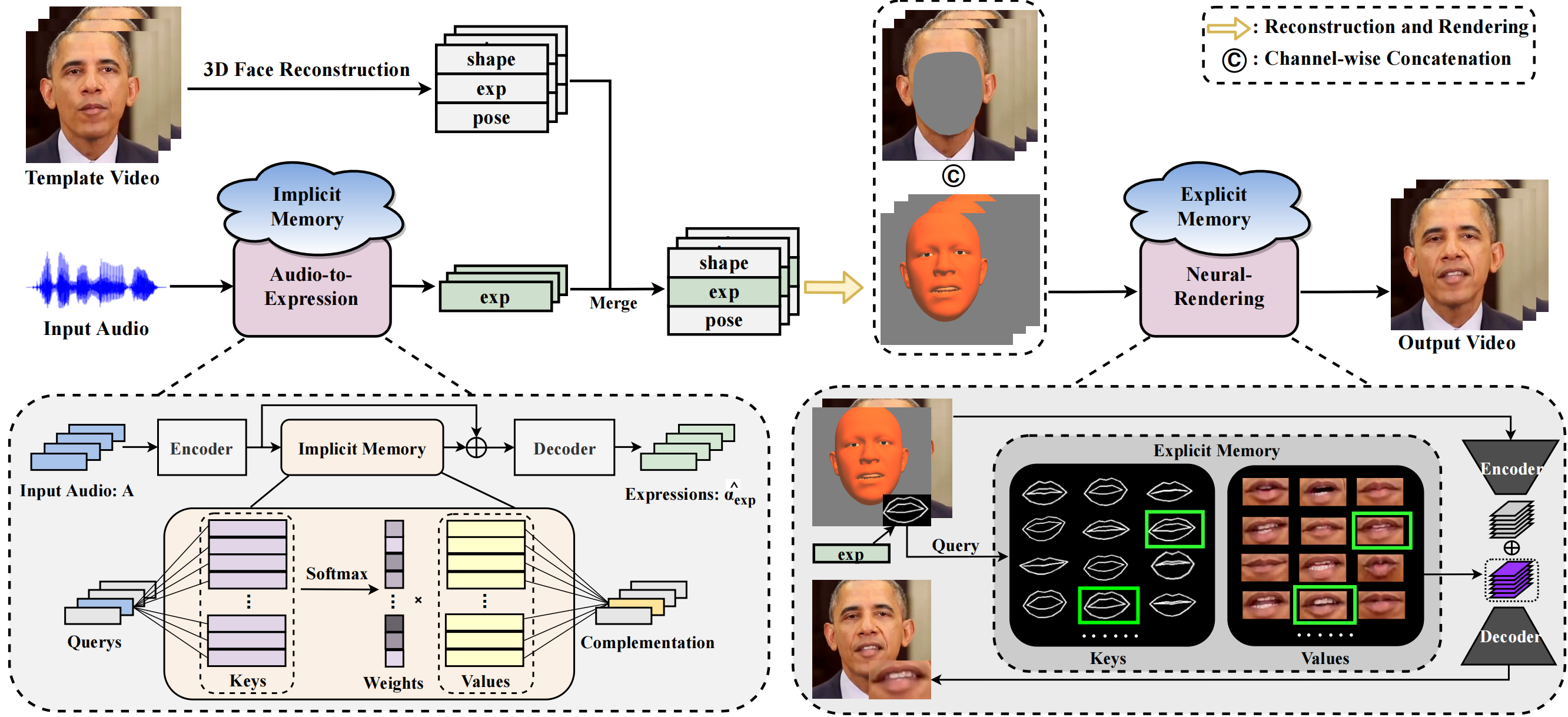
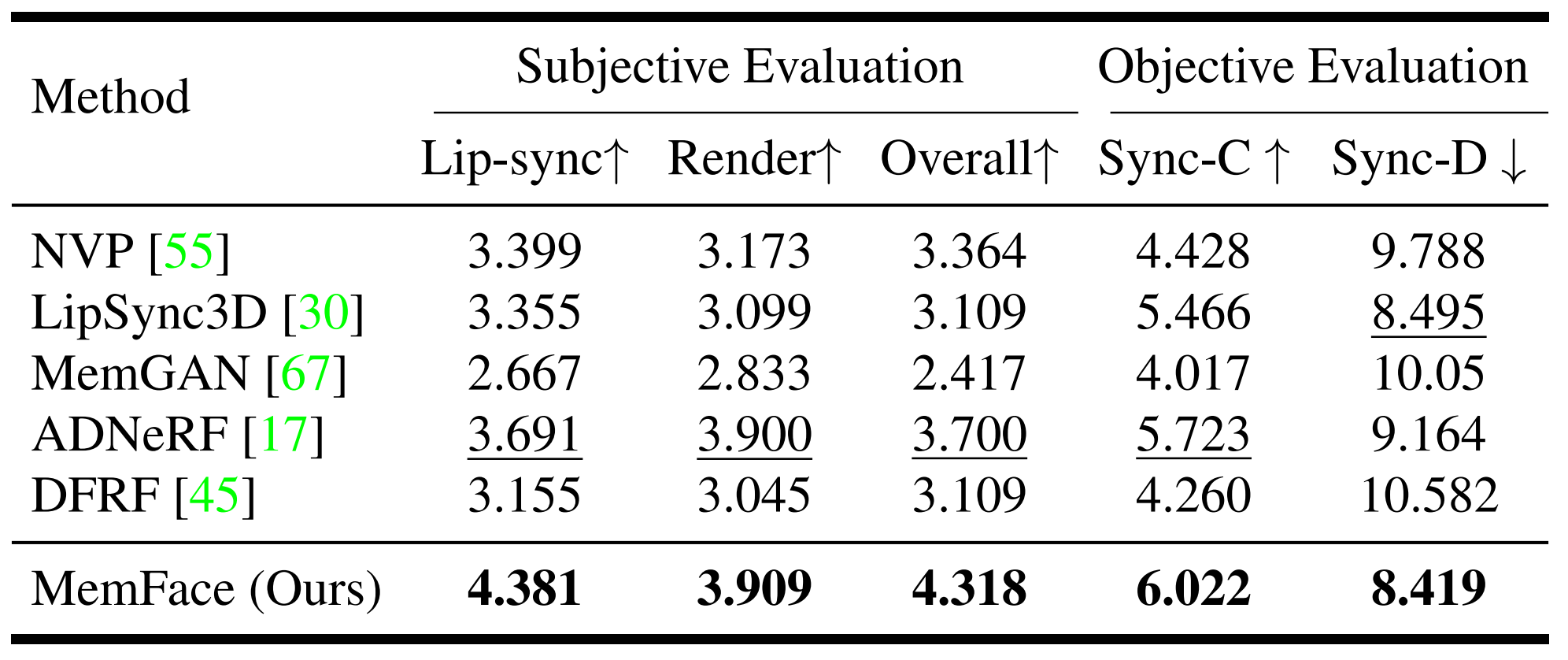
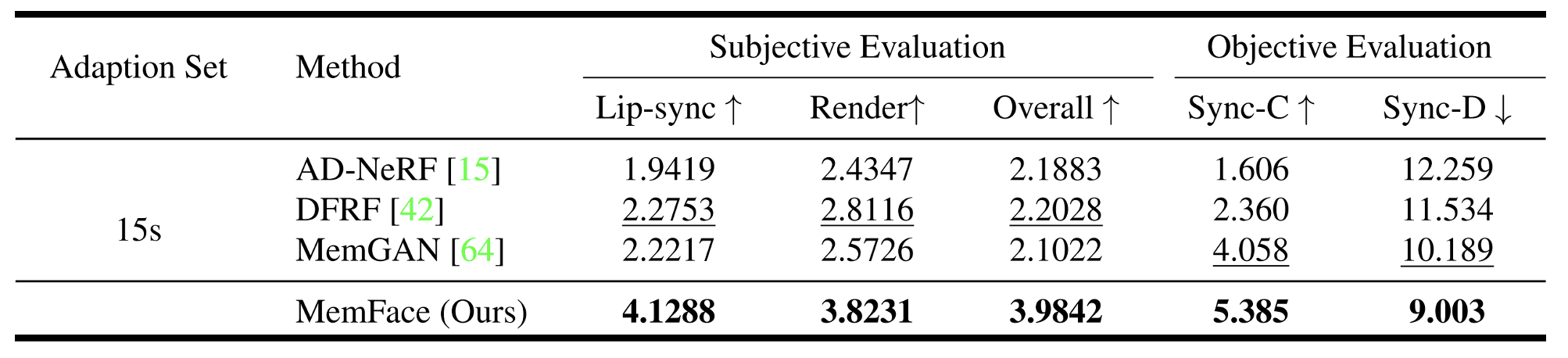
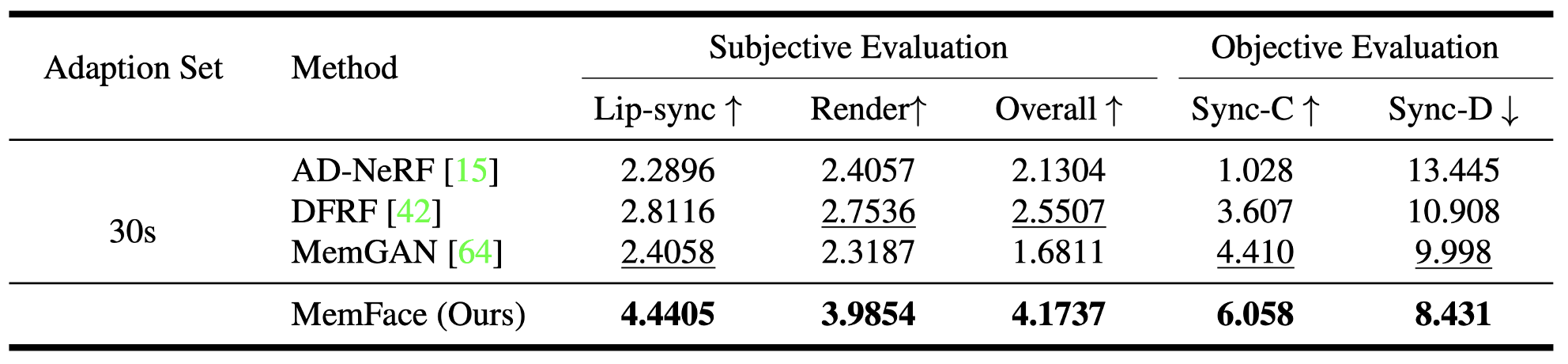
Method
To alleviate the one-to-many mapping difficulty, we propose to complement the missing information with memories. To this end, an implicit memory is introduced to the audio-to-expression model to complement the semantically-aligned information, while an explicit memory is introduced to the neural-rendering model to retrieve the personalized visual details.